Statistical Models
Why Not Machine Learning Models
- Better Interpretation: inference and prediction
- Prediction Accuracy: achieve similar performance compared to tree-based ML models
- Time Saving
- save training time
- no need for parameter tuning, cross-validation
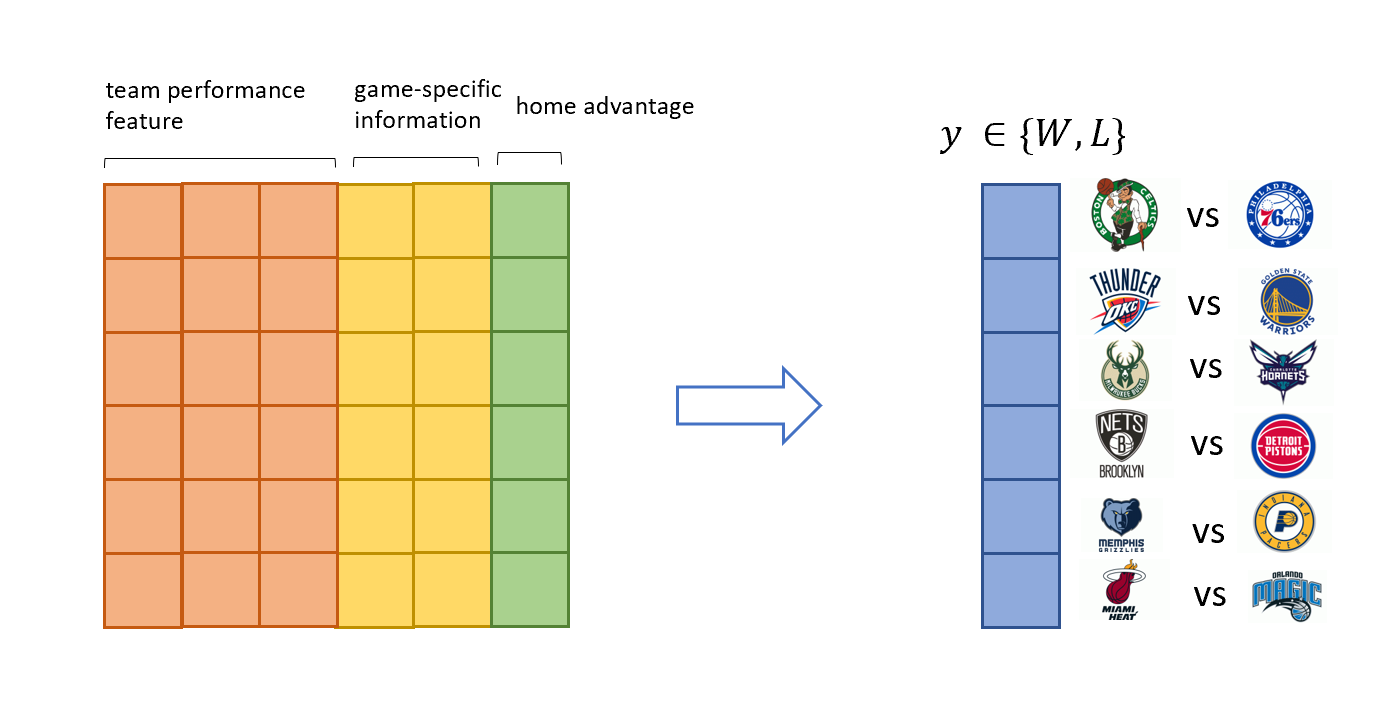
Model Formulation
where $\lambda_i$ and $\lambda_j$ are the team performance vectors defined based on feature engineering. $I(I \in adv)$ is the indicator for home-court advantage, and $z_{ij}$ are some potential effects not included in the team performance, such as western-eastern effect.
Evaluation Metric
Cross-Entropy Loss
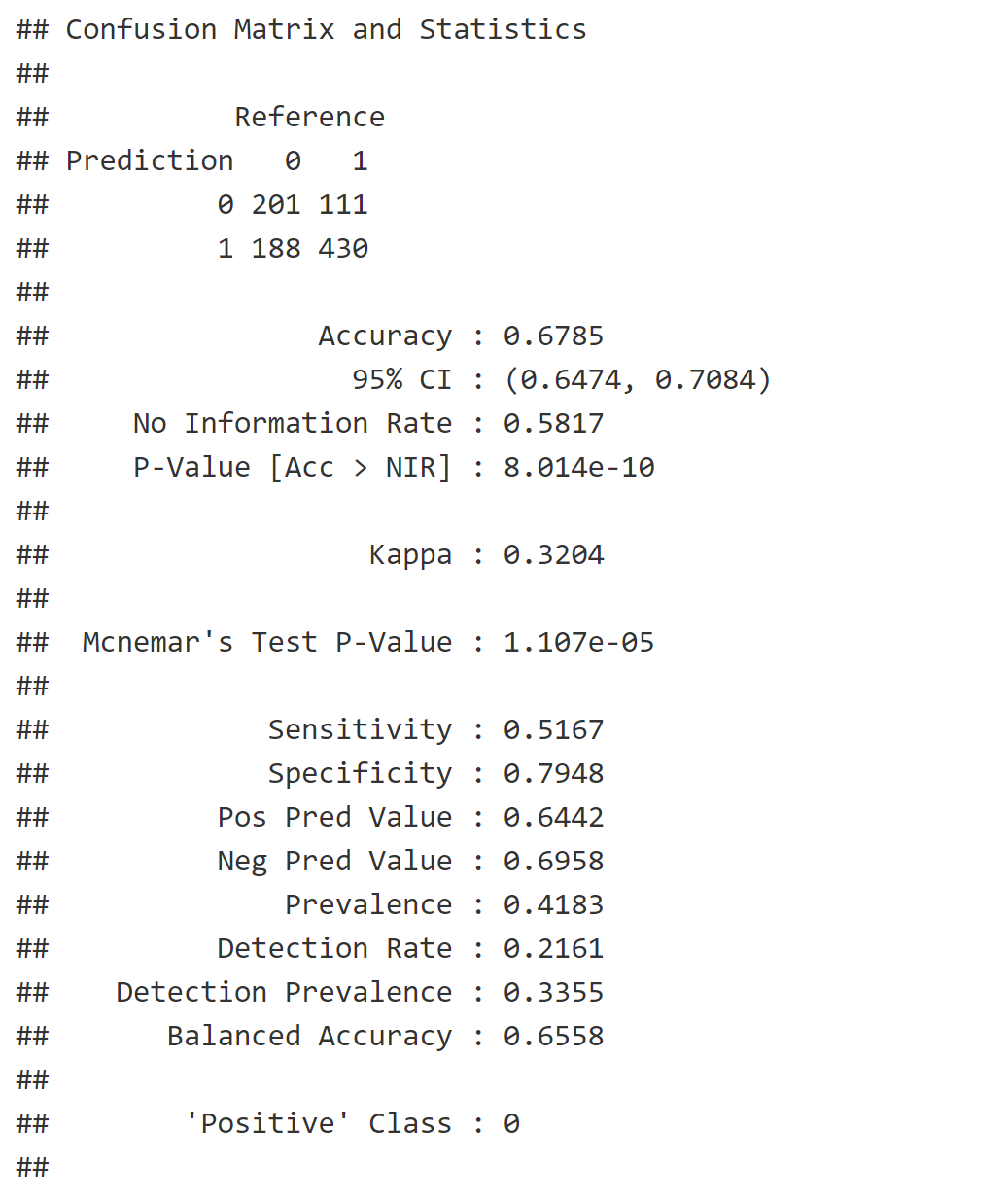
Prediction Results
Model Summary

Player-Level: Prediction Accuracy
Model Checking
- Overdispersion: quasi-likelihood approach